Delete Duplicates
Duplicate records in the database reduce data processing performance leading to inaccurate search and potential problems with keeping the integrity of the relational database.
So, how you can find and delete all duplicates from DBF files you have? Manually scanning all tables? There is a much better way, in fact. Name’s DBF Viewer 2000. Here are steps to remove doubling records from DBF using this software:
Step 1: Load the DBF file to DBF Viewer 2000
Let's see: there is a duplicate record in our database:
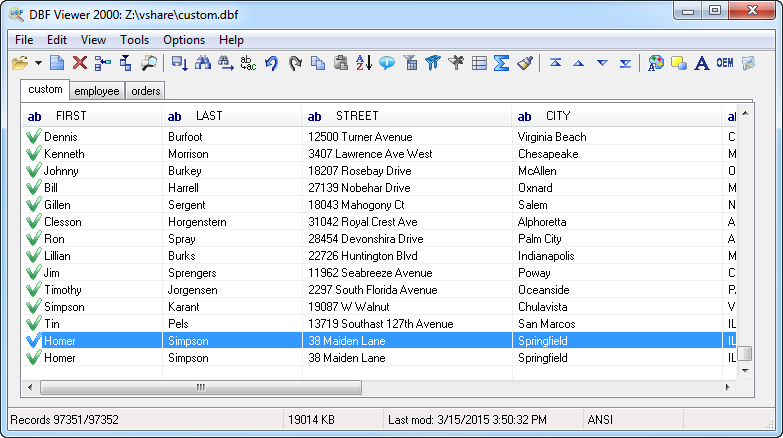
Of course, this is just a sample database file. In a real DBF file, there could be dozens of duplicates, and they will not be as easy to find among thousands of records.
Step 2: Choose the Delete Duplicates tool
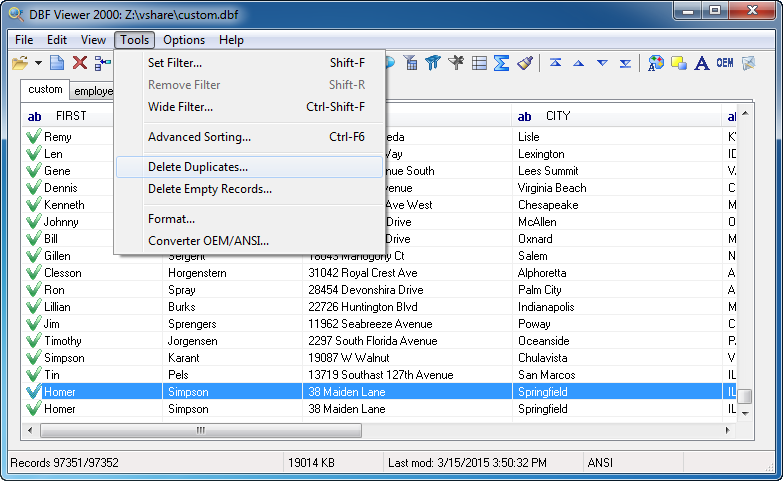
Step 3: Select fields of the dbf database to search duplicates for
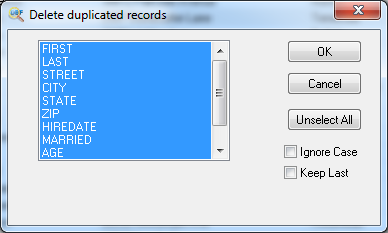
Here, you should select fields you want DBF Viewer 2000 to take into account when it determines if a record is a duplicate or not. By default, all fields are selected. This means records are duplicated only if all of their fields are the same. However, if you want, you can select certain fields here and DBF Viewer 2000 will delete all records that have the same value of these fields except one.
There are two options here. The Ignore Case option tells DBF Viewer 2000 to ignore character case of record values.
The Keep Last option overrides the default behavior of the tool to make it keep the last added record in the database (and remove all other duplicates) instead of the first one.
Delete duplicates via Command Line
"c:\Program Files (x86)\DBF Viewer 2000\dbview.exe" file.dbf /DELETEDUPS [/KEEPLAST | /BOTH]
Delete All duplicates
"c:\Program Files (x86)\DBF Viewer 2000\dbview.exe" file.dbf /DELETEDUPS /BOTH
Save First record
"c:\Program Files (x86)\DBF Viewer 2000\dbview.exe" file.dbf /DELETEDUPS
Save Last record
"c:\Program Files (x86)\DBF Viewer 2000\dbview.exe" file.dbf /DELETEDUPS /KEEPLAST
Delete in multiple files
"c:\Program Files (x86)\DBF Viewer 2000\dbview.exe" d:\mybase\*.dbf /DELETEDUPS
See also: DBF to Excel, DBF to CSV, DBF to SQL, command line options, Filtering records in dbf file
Back to DBF Viewer 2000 Home